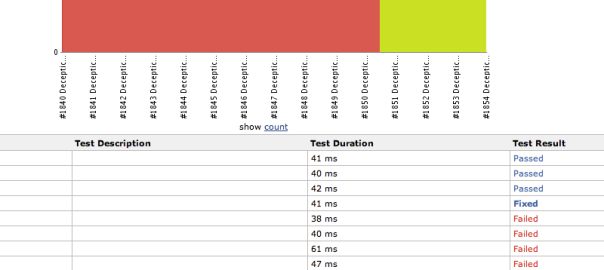
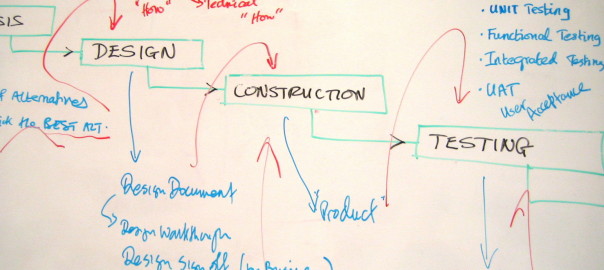
During a meeting recently, an open question came up along the lines of “code doesn’t rust, right?”. As a developer, I know this is not the case, because code rot, but I found it hard to describe the term succinctly. Code rot happens for many different reasons depending on the perspective you’re taking, and is linked to many other terms. Simply listing some of these seemed like both downplaying the problem and obfuscating the reasoning for addressing the problem behind jargon. These thoughts stayed in my mind afterwards, and I thought I’d have a look at how other people are describing it. Despite the general agreement on this Stack Exchange question that the Wikipedia description is poor, I actually felt it is a pretty good one:
Software rot, also known as code rot, bit rot, software erosion, software decay or software entropy describes the perceived “rot” which is either a slow deterioration of software performance over time or its diminishing responsiveness that will eventually lead to software becoming faulty, unusable, or otherwise called “legacy” and in need of upgrade. This is not a physical phenomenon: the software does not actually decay, but rather suffers from a lack of being responsive and updated with respect to the changing environment in which it resides.
I say this is a good description because it does not necessarily tie what is a fairly flexible term to one particular perspective, but also because it makes mention of two specific things:
Software entropy
The principle behind software entropy is that, as software is modified, its complexity, and thereby its entropy, increases. This link between complexity and entropy is what makes approaches such as KISS or YAGNI important in software development (more on this later). Entropy can (and indeed must) be mitigated through refactoring, but technical debt will increase entropy. And technical debt is interesting, because you already have some, even if you wrote your software yesterday. You might have only a small amount – that unit test you didn’t have time to write, or the documentation you didn’t think was necessary – but in any system with any history you will have accumulated some. Often there are business pressures behind that debt (and this is no comment on the business, because there are often good reasons for it). But that debt needs to be repaid, because the patchy solution that was traded off for an earlier release is going to come back and haunt you. Which leads nicely onto the second item…
A changing environment
With complex systems, the changes in the environment can be brought about by a staggering number of factors. Even when excluding hardware, new versions of operating systems, application servers, or browsers can break your product without touching a line of code. Protocols and standards change. Without realising it, your product has accumulated massive technical debt by not updating the frameworks and libraries chosen 10 years ago. That legacy part of your codebase? You know, the one no one wants to touch, ever, lest it collapse under its own weight, creating a black hole which pulls you right in, nullifying any concept of space and time? Yeah, it turns out that while it remained anchored in 2005 listening to Crazy Frog everything around it moved on and it doesn’t really work very well anymore, at least by modern standards. In other words, code which stagnates while everything around it fluctuates is rotting, and worse – it doesn’t even need to be buggy. What if your product is now too slow to compete with alternative products? If a particular feature runs noticeably slower than others or has a considerably different UI? If usability is poor? It is admittedly a very blurred line that gets drawn as to whether the culprit is poor design or maintenance (i.e. technical debt), or good old code rot, but the two are inextricably linked.
How did we get here?
So your code is now a soggy pile of rotting mush. How did it get there? As I mentioned earlier, the reasons for code rot are legion. Last year Quinn Norton wrote a particularly incisive article titled Everything Is Broken. The main focus of the article is on security, but there’s plenty to relate to software development in general, and I highly recommend you read the entire thing. Some particularly pertinent quotes:
Written by people with either no time or no money, most software gets shipped the moment it works well enough to let someone go home and see their family. What we get is mostly terrible.
Your average piece-of-shit Windows desktop is so complex that no one person on Earth really knows what all of it is doing, or how.
We’re back at complexity. This is an area which I’m familiar with from my experience so far, and why I feel that YAGNI is an important principle. As your product gains more features over time, so complexity increases, and inevitably so does software bloat. Preventing unnecessary complexity and bloat doesn’t just help to prevent code rot, it also reduces maintenance. On a long-term product, this is an important factor, as that expanded feature-set is necessarily going to require expanded maintenance.
But how do I fix it?
There is a tendency, when faced with overly complex code, to throw it out and start again. After all, it is nicer to play with a nice new ball than it is to play with a roughly spherical collection of patches. I include myself here – it is, or at least feels, harder to understand what old code you didn’t write does, than to start afresh asking the more fundamental question: what does this code need to do? When you are beyond the point at which refactoring is a realistic option, or when software bloat is severe enough, this is the right approach. Unfortunately, it is unlikely to be straightforward to recognise these situations if understanding the code is already a problem. Consider the possible time implications of addressing problem areas:
- Spend time understanding the code (tuc) and refactor (tr): t = tuc + tr
- Spend time understanding the code (tuc) and start over (ts): t = tuc + ts
- Spend time understanding the requirements (tur) and start over (ts): t = tur + ts
The tendency to start over comes from interpreting the above as tuc > tur, because tur is a subset of tuc so that option 2 is never worth it. Similarly, and as an independent consideration, it may be that ts > tr, but tr doesn’t reduce bloat or complexity, so ts is preferable. This means option 3 seems preferable. But logically, if tur is a subset of tuc, then it doesn’t follow that tr doesn’t reduce bloat or complexity, so option 1 is back in the game. It is also possible that ts < tr, putting option 2 in the mix too.
Long story cut short: it doesn’t matter what approach you take. Sure, some may take more time than you needed to, but what actually matters is addressing the problem.
Photo by pedrik via Flickr.